Виндовс 7 голосовом управлении домом. Команды для мыши
Какому пользователю компьютера не захотелось бы управлять им без помощи рук, то есть, не притрагиваясь к клавиатуре и мыши, а используя только свой голос? А для людей с ограниченными возможностями такая функция просто незаменима. Оригинальная (не русифицированная) версия Windows 7 имеет такую функцию, но она рассчитана только на английскую речь. Однако, и в русифицированной версии Windows 7 возможность голосового управления компьютером с Windows 7 можно ввести. Для этого существует несколько сторонних программ.
Это одна из наиболее распространенных утилит для голосового управления компьютером с Windows 7. Ее можно скачать с интернета. Она имеет две версии – бесплатную и платную (premium). Ниже пойдет речь о бесплатной версии.
После запуска программа выдает свое главное окно:

 В нем нужно задать имя пользователя и текстовое содержание команды. После чего следует нажать красную кнопку (запись) и сказать в микрофон нужную команду, например, «открой зип сэвен». Затем нажать кнопку «добавить». Этими действиями в утилите создается звуковой образ команды управления.
В нем нужно задать имя пользователя и текстовое содержание команды. После чего следует нажать красную кнопку (запись) и сказать в микрофон нужную команду, например, «открой зип сэвен». Затем нажать кнопку «добавить». Этими действиями в утилите создается звуковой образ команды управления.
Следующее действие – это привязка заданного звукового образа к конкретной программе или файлу на компьютере. Для этого нужно кликнуть в главном окне по кнопке
И установить галочку на нужном нам пункте:
Появляется список установленных программ компьютера, в котором следует выбрать 7-Zip File Manager. Затем необходимо нажать на «запись» и «Добавить».

После этого в главном окне в профиль пользователя добавится созданная команда:
Теперь остается только проверить ее выполнение. Для этого нужно в главном окне нажать «Начать говорить» и произнести заветную фразу «Открой зип сэвен, после чего утилита 7-zip откроется.
К сожалению, нельзя сказать, что Typle во всех случаях правильно распознает русскую речь, но это недостаток большинства программ распознавания голоса.
Программа Speechka для голосового управления компьютером с Windows 7
Speechka представляет собой простую и удобную программу, распознающую русский язык. Эта утилита позволяет голосом открывать программы, файлы, папки и интернет-страницы, производить поиск в Интернете. Программа бесплатная и легко скачивается и устанавливается.
Вот выглядит ее главное окно:
 В зависимости от своих намерений пользователь должен нажать одну из кнопок главного окна. После нажатия одной из них справа от главного окна появляется окно для задания параметров голосовой команды. Например, при нажатии «Интернет» откроется окошко такого вида:
В зависимости от своих намерений пользователь должен нажать одну из кнопок главного окна. После нажатия одной из них справа от главного окна появляется окно для задания параметров голосовой команды. Например, при нажатии «Интернет» откроется окошко такого вида:
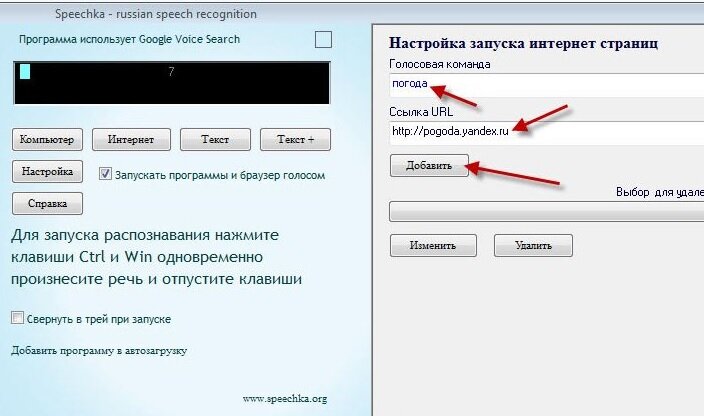 В нем уже показаны настройки, необходимые для запуска страницы Яндекса с прогнозом погоды. После нажатия кнопки «Добавить» необходимо озвучить данную команду. Это делается, как указано на главной странице, одновременным нажатием «Ctrl» и «Win», после чего нужно сказать в микрофон слово или фразу, например «погода», и отпустить клавиши. В настройках программы есть возможность активировать запись звука по комбинации «Ctrl» + «Win», либо просто по уровню звука.
В нем уже показаны настройки, необходимые для запуска страницы Яндекса с прогнозом погоды. После нажатия кнопки «Добавить» необходимо озвучить данную команду. Это делается, как указано на главной странице, одновременным нажатием «Ctrl» и «Win», после чего нужно сказать в микрофон слово или фразу, например «погода», и отпустить клавиши. В настройках программы есть возможность активировать запись звука по комбинации «Ctrl» + «Win», либо просто по уровню звука.
Кстати, проверить работу этой утилиты с микрофоном и отрегулировать его громкость можно сразу после запуска программы, сказав несколько слов в микрофон. Если индикатор уровня не отвечает, то есть проблемы с подключением микрофона или с недостаточным уровнем его громкости.
Еще до релиза находящегося на стадии разработки, тестирования и отладки интерфейса Cortana для Windows 10 пользователи пытались организовать голосовое управление компьютера. О том, как такую функцию можно реализовать в Windows, вышедших до 10-ки и поговорим в сегодняшней статье.
Cortana
Кортана – голосовой помощник с ИИ, разработанный корпорацией Microsoft для Windows 10, Phone и Android с дальнейшим распространением проекта на XBox и iOS. Она заменяет классическую поисковую строку и выполняет множество действий, в первую очередь, связанных с поиском информации и системных команд, получая их от пользователя в виде голосовых команд. Глубокая интеграция в Windows 10, отсутствие русского языка (пока что), сбор фактически всей информации о пользователе с отправкой на серверы Microsoft и отсутствие финальной версии не дают возможности большинству пользователей получить полноценное голосовое управление собственным компьютером.
Помимо Кортаны существует немало приложений, позволяющих осуществлять управление ПК посредством голосовых команд пользователя. Ознакомимся с самыми распространенными продуктами для решения этой задачи в Windows 7 и 10.
Typle
Приложение занимает лидирующие позиции среди русскоязычных пользователей, желающих командовать компьютером посредством голоса. Утилита с легкостью заменит значительную часть функций Кортаны на Windows 10, а на «семерке» добавит функцию, нередко демонстрируемую в фильмах, где люди управляют компьютерами при помощи голоса.

Перед началом работы создаем учетную запись и придумываем ключевую фразу, услышав которую приложение активируется. Затем задаем голосовую команду по управлению компьютером или выполнению определенного действия и закрепляем за ней операцию (запуск приложения, переход на указанный сайт). В окне редактирования созданных команд появляется возможность задавать параметры, с которыми приложение будет запускаться, и указать режим запуска (полноэкранный, оконный).
Функционал утилиты весьма ограничен, а интерфейсу далеко до стиля Метро, реализованного в Windows 10. Полноценное голосовое управление ПК посредством Typle реализовать не удастся: она поддерживает только открытие файлов, приложений (с аргументами) и переход по заранее заданным ссылкам. Отсутствует даже поддержка управления проигрывателем (поставить на паузу, запустить следующий трек).
Speaker
- создание снимков состояния экрана;
- переключение раскладки клавиатуры;
- завершение работы Windows 7;
- запуск приложения;
- открытие файла.
Процесс считывания и распознавания поступающей на микрофон информации запускается после нажатия на заданную клавишу (лучше выбирайте кнопку, наименее редко используемую вами во избежание ложных срабатываний программы). На обработку, распознание речи и выполнение команды уходит достаточно много времени – 5 и более секунд, чем придется заплатить за дешевизну. Ключевые слова задаются текстом, а не словами, потому распознанная речь сравнивается уже с введенным текстом, что делается далеко не идеально. Управление проигрывателем в приложении отсутствует.
Горыныч
Разработчики программного комплекса для управления компьютером с Windows 7 и 10 являются первой отечественной командой, выпустившей приложение для решения подобного рода задач. За ядро приложения взята западная «Dragon Dictate», куда внедрили отечественный программный модуль для распознания русской речи.
Ко мне обратился человек с просьбой написать программу, которая позволила бы управлять компьютерной мышью при помощи голоса. Тогда я и представить себе не мог, что, практически полностью парализованный человек, который даже не может сам повернуть голову, а может лишь разговаривать, способен развить бурную деятельность, помогая себе и другим жить активной жизнью, получать новые знания и навыки, работать и зарабатывать, общаться с другими людьми по всему свету, участвовать в конкурсе социальных проектов.Позволю себе привести здесь пару ссылок на сайты, автором и/или идейным вдохновителем которых является этот человек – Александр Макарчук из города Борисов, Беларусь:
Для работы на компьютере Александр использовал программу «Vocal Joystick» - разработку студентов Университета штата Вашингтон, выполненную на деньги Национального Научного Фонда (NSF). См. melodi.ee.washington.edu/vj
Не удержался
Кстати, на сайте университета (http://www.washington.edu/) 90% статей именно про деньги. Трудно найти что-нибудь про научную работу. Вот, например, выдержки с первой страницы: «Том, выпускник университета, раньше питался грибами и с трудом платил за квартиру. Теперь он старший менеджер ИТ-компании и кредитует университет», «Большие Данные помогают бездомным», «Компания обязалась заплатить 5 миллионов долларов за новый учебный корпус».
Это одному мне режет глаз?
Программа была сделана в 2005-2009 годах и хорошо работала на Windows XP. В более свежих версиях Windows программа может зависнуть, что неприемлемо для человека, который не может встать со стула и её перезапустить. Поэтому программу нужно было переделать.
Исходных текстов нет, есть только отдельные публикации, приоткрывающие технологии, на которых она основана (MFCC, MLP – читайте об этом во второй части).
По образу и подобию была написана новая программа (месяца за три).
Собственно, посмотреть, как она работает, можно :
Скачать программу и/или посмотреть исходные коды можно .
Никаких особенных действий для установки программы выполнять не надо, просто щёлкаете на ней, да запускаете. Единственное, в некоторых случаях требуется, чтобы она была запущена от имени администратора (например, при работе с виртуальной клавиатурой “Comfort Keys Pro”):

Пожалуй, стоит упомянуть здесь и о других вещах, которые я ранее делал для того, чтобы можно было управлять компьютером без рук.
Если у вас есть возможность поворачивать голову, то хорошей альтернативой eViacam может послужить гироскоп, крепящийся к голове. Вы получите быстрое и точное позиционирование курсора и независимость от освещения.
Если вы можете двигать только зрачками глаз, то можно использовать трекер направления взгляда и программу к нему (могут быть сложности, если вы носите очки).
Часть II. Как это устроено?
Из опубликованных материалов о программе «Vocal Joystick» было известно, что работает она следующим образом:- Нарезка звукового потока на кадры по 25 миллисекунд с перехлёстом по 10 миллисекунд
- Получение 13 кепстральных коэффициентов (MFCC) для каждого кадра
- Проверка того, что произносится один из 6 запомненных звуков (4 гласных и 2 согласных) при помощи многослойного персептрона (MLP)
- Воплощение найденных звуков в движение/щелчки мыши
Последняя задача просто реализуется при помощи функции SendInput.
Наибольший же интерес, мне кажется, представляют вторая и третья задачи. Итак.
Задача №2. Получение 13 кепстральных коэффициентов
Если кто не в теме – основная проблема узнавания звуков компьютером заключается в следующем: трудно сравнить два звука, так как две непохожие по очертанию звуковые волны могут звучать похоже с точки зрения человеческого восприятия.И среди тех, кто занимается распознаванием речи, идёт поиск «философского камня» - набора признаков, которые бы однозначно классифицировали звуковую волну.
Из тех признаков, что доступны широкой публике и описаны в учебниках, наибольшее распространение получили так называемые мел-частотные кепстральные коэффициенты (MFCC).
История их такова, что изначально они предназначались совсем для другого, а именно, для подавления эха в сигнале (познавательную статью на эту тему написали уважаемые Оппенгейм и Шафер, да пребудет радость в домах этих благородных мужей. См. A. V. Oppenheim and R.W. Schafer, “From Frequency to Quefrency: A History of the Cepstrum”).
Но человек устроен так, что он склонен использовать то, что ему лучше знакомо. И тем, кто занимался речевыми сигналами, пришло в голову использовать уже готовое компактное представление сигнала в виде MFCC. Оказалось, что, в общем, работает. (Один мой знакомый, специалист по вентиляционным системам, когда я его спросил, как бы сделать дачную беседку, предложил использовать вентиляционные короба. Просто потому, что их он знал лучше других строительных материалов).
Являются ли MFCC хорошим классификатором для звуков? Я бы не сказал. Один и тот же звук, произнесённый мною в разные микрофоны, попадает в разные области пространства MFCC-коэффициентов, а идеальный классификатор нарисовал бы их рядом. Поэтому, в частности, при смене микрофона вы должны заново обучать программу.

Это всего лишь одна из проекций 13-мерного пространства MFCC в 3-мерное, но и на ней видно, что я имею в виду – красные, фиолетовые и синие точки получены от разных микрофонов: (Plantronix, встроенный массив микрофонов, Jabra), но звук произносился один.
Однако, поскольку ничего лучшего я предложить не могу, также воспользуюсь стандартной методикой – вычислением MFCC-коэффициентов.
Чтобы не ошибиться в реализации, в первых версиях программы в качестве основы был использован код из хорошо известной программы CMU Sphinx, точнее, её реализации на языке C, именующейся pocketsphinx, разработанной в Университете Карнеги-Меллона (мир с ними обоими! (с) Хоттабыч).
Исходные коды pocketsphinx открыты, да вот незадача – если вы их используете, то должны в своей программе (как в исходниках, так и в исполняемом модуле) прописать текст, содержащий, в том числе, следующее:
* This work was supported in part by funding from the Defense Advanced
* Research Projects Agency and the National Science Foundation of the
* United States of America, and the CMU Sphinx Speech Consortium.
Мне это показалось неприемлемым, и пришлось код переписать. Это сказалось на быстродействии программы (в лучшую сторону, кстати, хотя «читабельность» кода несколько пострадала). Во многом благодаря использованию библиотек “Intel Performance Primitives”, но и сам кое-что оптимизировал, вроде MEL-фильтра. Тем не менее, проверка на тестовых данных показала, что получаемые MFCC-коэффициенты полностью аналогичны тем, что получаются при помощи, например, утилиты sphinx_fe.
В программах sphinxbase вычисление MFCC-коэффициентов производится следующими шагами:
| Шаг | Функция sphinxbase | Суть операции |
|---|---|---|
| 1 | fe_pre_emphasis | Из текущего отсчёта вычитается большая часть предыдущего отсчета (например, 0.97 от его значения). Примитивный фильтр, отбрасывающий нижние частоты. |
| 2 | fe_hamming_window | Окно Хемминга – вносит затухание в начале и конце кадра |
| 3 | fe_fft_real | Быстрое преобразование Фурье |
| 4 | fe_spec2magnitude | Из обычного спектра получаем спектр мощности, теряя фазу |
| 5 | fe_mel_spec | Группируем частоты спектра [например, 256 штук] в 40 кучек, используя MEL-шкалу и весовые коэффициенты |
| 6 | fe_mel_cep | Берём логарифм и применяем DCT2-преобразование к 40 значениям из предыдущего шага. Оставляем первые 13 значений результата. Есть несколько вариантов DCT2 (HTK, legacy, классический), отличающихся константой, на которую мы делим полученные коэффициенты, и особой константой для нулевого коэффициента. Можно выбрать любой вариант, сути это не изменит. |
В эти шаги ещё вклиниваются функции, которые позволяют отделить сигнал от шума и от тишины, типа fe_track_snr, fe_vad_hangover, но нам они не нужны, и отвлекаться на них не будем.
Были выполнены следующие замены для шагов по получению MFCC-коэффициентов:
Задача №3. Проверка того, что произносится один из 6 запомненных звуков
В программе-оригинале «Vocal Joystick» для классификации использовался многослойный персептрон (MLP) – нейронная сеть без новомодных наворотов.Давайте посмотрим, насколько оправдано применение нейронной сети здесь.
Вспомним, что делают нейроны в искусственных нейронных сетях.
Если у нейрона N входов, то нейрон делит N-мерное пространство пополам. Рубит гиперплоскостью наотмашь. При этом в одной половине пространства он срабатывает (выдаёт положительный ответ), а в другой – не срабатывает.
Давайте посмотрим на [практически] самый простой вариант – нейрон с двумя входами. Он, естественно, будет делить пополам двумерное пространство.
Пусть на вход подаются значения X1 и X2, которые нейрон умножает на весовые коэффициенты W1 и W2, и добавляет свободный член C.

Итого, на выходе нейрона (обозначим его за Y) получаем:
Y=X1*W1+X2*W2+C
(опустим пока тонкости про сигмоидальные функции)
Считаем, что нейрон срабатывает, когда Y>0. Прямая, заданная уравнением 0=X1*W1+X2*W2+C как раз и делит пространство на часть, где Y>0, и часть, где Y<0.
Проиллюстрируем сказанное конкретными числами.
Пусть W1=1, W2=1, C=-5;

Теперь посмотрим, как нам организовать нейронную сеть, которая бы срабатывала на некоторой области пространства, условно говоря – пятне, и не срабатывала во всех остальных местах.
Из рисунка видно, что для того, чтобы очертить область в двумерном пространстве, нам потребуется по меньшей мере 3 прямых, то есть 3 связанных с ними нейрона.

Эти три нейрона мы объединим вместе при помощи ещё одного слоя, получив многослойную нейронную сеть (MLP).

А если нам нужно, чтобы нейронная сеть срабатывала в двух областях пространства, то потребуется ещё минимум три нейрона (4,5,6 на рисунках):
И тут уж без третьего слоя не обойтись:
А третий слой – это уже почти Deep Learning…

Теперь обратимся за помощью к ещё одному примеру. Пусть наша нейронная сеть должна выдавать положительный ответ на красных точках, и отрицательный – на синих точках.

Если бы меня попросили отрезать прямыми красное от синего, то я бы сделал это как-то так:

Но нейронная сеть априори не знает, сколько прямых (нейронов) ей понадобится. Этот параметр надо задать перед обучением сети. И делает это человек на основе… интуиции или проб и ошибок.
Если мы выберем слишком мало нейронов в первом слое (три, например), то можем получить вот такую нарезку, которая будет давать много ошибок (ошибочная область заштрихована):

Но даже если число нейронов достаточно, в результате тренировки сеть может «не сойтись», то есть достигнуть некоторого стабильного состояния, далёкого от оптимального, когда процент ошибок будет высок. Как вот здесь, верхняя перекладина улеглась на два горба и никуда с них не уйдёт. А под ней большая область, порождающая ошибки:

Снова, возможность таких случаев зависит от начальных условий обучения и последовательности обучения, то есть от случайных факторов:
- Что ты думаешь, доедет то колесо, если б случилось, в Москву или не доедет?
- А ты как думаешь, сойдётся ента нейронная сеть или не сойдётся?
Есть ещё один неприятный момент, связанный с нейронными сетями. Их «забывчивость».
Если начать скармливать сети только синие точки, и перестать скармливать красные, то она может спокойно отхватить себе кусок красной области, переместив туда свои границы:

Если у нейронных сетей столько недостатков, и человек может провести границы гораздо эффективнее нейронной сети, зачем же их тогда вообще использовать?
А есть одна маленькая, но очень существенная деталь.
Я очень хорошо могу отделить красное сердечко от синего фона отрезками прямых в двумерном пространстве.
Я неплохо смогу отделить плоскостями статую Венеры от окружающего её трёхмерного пространства.
Но в четырёхмерном пространстве я не смогу ничего, извините. А в 13-мерном - тем более.
А вот для нейронной сети размерность пространства препятствием не является. Я посмеивался над ней в пространствах малой размерности, но стоило выйти за пределы обыденного, как она меня легко уделала.
Тем не менее вопрос пока открыт – насколько оправдано применение нейронной сети в данной конкретной задаче, учитывая перечисленные выше недостатки нейронных сетей.
Забудем на секунду, что наши MFCC-коэффициенты находятся в 13-мерном пространстве, и представим, что они двумерные, то есть точки на плоскости. Как в этом случае можно было бы отделить один звук от другого?
Пусть MFCC-точки звука 1 имеют среднеквадратическое отклонение R1, что [грубо] означает, что точки, не слишком далеко отклоняющиеся от среднего, наиболее характерные точки, находятся внутри круга с радиусом R1. Точно так же точки, которым мы доверяем у звука 2 находятся внутри круга с радиусом R2.

Внимание, вопрос: где провести прямую, которая лучше всего отделяла бы звук 1 от звука 2?
Напрашивается ответ: посередине между границами кругов. Возражения есть? Возражений нет.
Исправление:
В программе эта граница делит отрезок, соединяющий центры кругов в соотношении R1:R2, так правильнее.


И, наконец, не забудем, что где-то в пространстве есть точка, которая является представлением полной тишины в MFCC-пространстве. Нет, это не 13 нулей, как могло бы показаться. Это одна точка, у которой не может быть среднеквадратического отклонения. И прямые, которыми мы отрежем её от наших трёх звуков, можно провести прямо по границам окружностей:

На рисунке ниже каждому звуку соответствует кусок пространства своего цвета, и мы можем всегда сказать, к какому звуку относится та или иная точка пространства (или не относится ни к какому):

Ну, хорошо, а теперь вспомним, что пространство 13-мерное, и то, что было хорошо рисовать на бумаге, теперь оказывается тем, что не укладывается в человеческом мозгу.
Так, да не так. К счастью, в пространстве любой размерности остаются такие понятия, как точка, прямая, [гипер]плоскость, [гипер]сфера.
Мы повторяем все те же действия и в 13-мерном пространстве: находим дисперсию, определяем радиусы [гипер]сфер, соединяем их центры прямой, рубим её [гипер]плоскостью в точке, равно отдалённой от границ [гипер]сфер.
Никакая нейронная сеть не сможет более правильно отделить один звук от другого.
Здесь, правда, следует сделать оговорку. Всё это справедливо, если информация о звуке – это облако точек, отклоняющихся от среднего одинаково во всех направлениях, то есть хорошо вписывающееся в гиперсферу. Если бы это облако было фигурой сложной формы, например, 13-мерной изогнутой сосиской, то все приведённые выше рассуждения были бы не верны. И возможно, при правильном обучении, нейронная сеть смогла бы показать здесь свои сильные стороны.
Но я бы не рисковал. А применил бы, например, наборы нормальных распределений (GMM), (что, кстати и сделано в CMU Sphinx). Всегда приятнее, когда ты понимаешь, какой конкретно алгоритм привёл к получению результата. А не как в нейронной сети: Оракул, на основе своего многочасового варения бульона из данных для тренировки, повелевает вам принять решение, что запрашиваемый звук – это звук №3. (Меня особенно напрягает, когда нейронной сети пытаются доверить управление автомобилем. Как потом в нестандартной ситуации понять, из-за чего машина повернула влево, а не вправо? Всемогущий Нейрон повелел?).
Но наборы нормальных распределений – это уже отдельная большая тема, которая выходит за рамки этой статьи.
Надеюсь, что статья была полезной, и/или заставила ваши мозговые извилины поскрипеть.
Чаще всего при работе за персональным компьютером нам приходится набирать тексты большого объема. Сидя непосредственно перед монитором, мы теряем много времени, хотя могли бы совершать какие-либо дела по дому.
Прошлый век
Разберёмся, что такое голосовое управление компьютером. Проведём некоторую аналогию. Раньше, да и сейчас, очень распространённым способом "освободить руки" от компьютера во время работы являлся найм ещё одного сотрудника - стенографиста или секретаря. Однако мало кто знает, что можно избежать лишних трат путём установки на персональный компьютер ряда программ и утилит, позволяющих осуществлять голосовое управление компьютером на русском языке.
С появлением таких программных продуктов, как "Горыныч" и WebSpeach, вы можете забыть о том, как долгими часами приходилось сидеть и печатать какую-либо работу, например, диплом, приказ или любую другую документацию. С развитием компьютерных технологий появился вариант использования специальной программы распознавания речи.
Встроенные утилиты
Голосовое управление компьютером Windows 8 осуществляется с помощью встроенной утилиты Windows Speech Recognition. К сожалению, в настоящий момент управление компьютером на русском языке невозможно. Компания Microsoft, во всей видимости, старается ориентироваться на наиболее распространённые языки, однако не исключено, что в скором времени будет выпущена поддержка и русского языка.
Если же вы всё-таки хотите попробовать управлять своим железным товарищем с помощью английского языка, следуйте следующей инструкции.
- Заходите в панель управления в подпункт "Язык". Вам необходимо установить язык системы - английский. Если он у вас отсутствует, то вам потребуется загрузить соответствующий языковой пакет.
- После загрузки и установки языка переходим в начальный экран с "плиткой".
- Вводим в поиск Windows Speech Recognition и нажимаем Enter. Так запускается программа распознавания голоса.
- При первом запуске вам будет предложено настроить микрофон. Выберите вашу разновидность и произнесите пару слов.
- Затем вам будет предложен 20-минутный обучающий курс. Он проводится на английском, поэтому, если вы не понимаете язык, можете смело его пропускать. Интерфейс у программы абсолютно понятный, поэтому разобраться с ним сможет даже ребёнок.
- Чтобы включить голосовое управление компьютером, вам будет необходимо произнести ключевую фразу "Start listening". Это означает - "начать прослушивание". Теперь можете запускать необходимую вам программу и начинать надиктовывать текст.

Вообще, возможности этой утилиты неисчерпаемы. Кроме использования базовых команд, вы также можете создавать свои.
Развитие
Было создано множество приложений для распознавания русской и английской речи:
- "Диктограф 5";
- "Перпетуум мобиле";
- Voice_PE;
- Lucent;
- VoiceType;
- Sakrament.

Однако наибольшую популярность набрали:
- "Горыныч";
- Web Speech;
- RealSpeaker;
- Speechka.
Займёмся их более подробным рассмотрением.
"Горыныч"
Как можно понять из названия, приложение было создано командой русских программистов и получило название в честь русского сказочного персонажа с именем Горыныч. Голосовое управление компьютером в ней осуществляется на русском языке, впрочем, имеется также и поддержка английского. "Горыныч" позволяет управлять персональным компьютером в пользовательском режиме, то есть совершать все возможные действия, которые вы можете производить с помощью мышки и клавиатуры: работа с окнами, приложениями, процессами, запущенными на персональном компьютере. Более того, "Горыныч" распознаёт речь исключительно одного хозяина, но не всегда.

Однако существует один достаточно большой недостаток. Дело в том, что всю базу команд вам необходимо вводить вручную. То есть, перед тем как вы сможете хоть что-то сделать на компьютере голосом, вам необходимо создать целую базу с записанными вашим голосом командами. Даже если вы это сделаете, в случае если вы вдруг охрипнете или поменяется хоть немного тембр голоса, "Горыныч" напрочь откажется вас понимать.
Очередной подводный камень заключается в том, что если вы хотите надиктовывать тексты на компьютер, вам предварительно потребуется создать огромный словарь для "Горыныча" с хорошим словарным запасом, чтобы он смог понять то, что вы диктуете.
Speechka

Обеспечить это могут помочь сторонние приложения, устанавливаемые на персональный компьютер. Одним из них является Speechka. Так же, как и "Горыныч", русский продукт, созданный на основе технологий Google, "Спичка" позволяет пользователю с помощью заданного набора команд осуществлять голосовое управление компьютером. Speechka достаточно неплохо распознаёт любую речь, и для неё нет необходимости записывать звуковые файлы. Достаточно просто с клавиатуры ввести слово и ассоциировать его с каким-либо действием. Проще говоря, это достойный существования продукт, однако находящийся на стадии разработки, поскольку такие функции, как закрытие окон или запуск программ были добавлены сравнительно недавно.
Набор текста
Разобравшись, что такое голосовое управление компьютером, рассмотрим проблему набора текста. Как было уже сказано, не все приложения позволяют его производить. В большинстве случаев для этого необходимо предварительно составить целый словарь, а если вы являетесь пользователем Windows 8, то еще возникает проблема поддержки русской речи. Для того чтобы решить эту проблему, существует сервис голосового набора, созданный Google.
Доступное только для браузеров Chrome, приложение Google Web Speech распознаёт 32 ведущих мировых языка, в том числе и русский. Для того чтобы вводить текст голосом, вам потребуется соответствующий браузер, Интернет и микрофон. Разработки продвинулись достаточно далеко, поэтому эта утилита способна воспринимать грамотную русскую речь целыми словами и переводить её в печатный текст.

Еще одна программа для распознания речи и надиктовки её на персональный компьютер - RealSpeaker. Она использует современные технологии распознавания мимики лица. Для её использования подойдёт абсолютно любая веб-камера. Единственное неудобство, которое возникает при работе, это то, что лицо говорящего должно быть точно напротив камеры, на расстоянии не более 40 сантиметров. В этой программе существует словарь русского языка, который пользователь при желании может расширить. В целом эта программа намного удобнее "Горыныча".
Итог
Если вы задумались об управлении компьютером голосом, поверьте, это пока не для России. Адекватные программы распознавания на сегодняшний день существуют только на английском языке, а автоматический голосовой набор текста будет содержать столько ошибок, что будет проще написать текст с нуля, чем исправлять все опечатки. Вы, конечно, можете постараться выучить английский язык и управлять компьютером на нём, однако вам потребуется идеальная дикция и произношение.